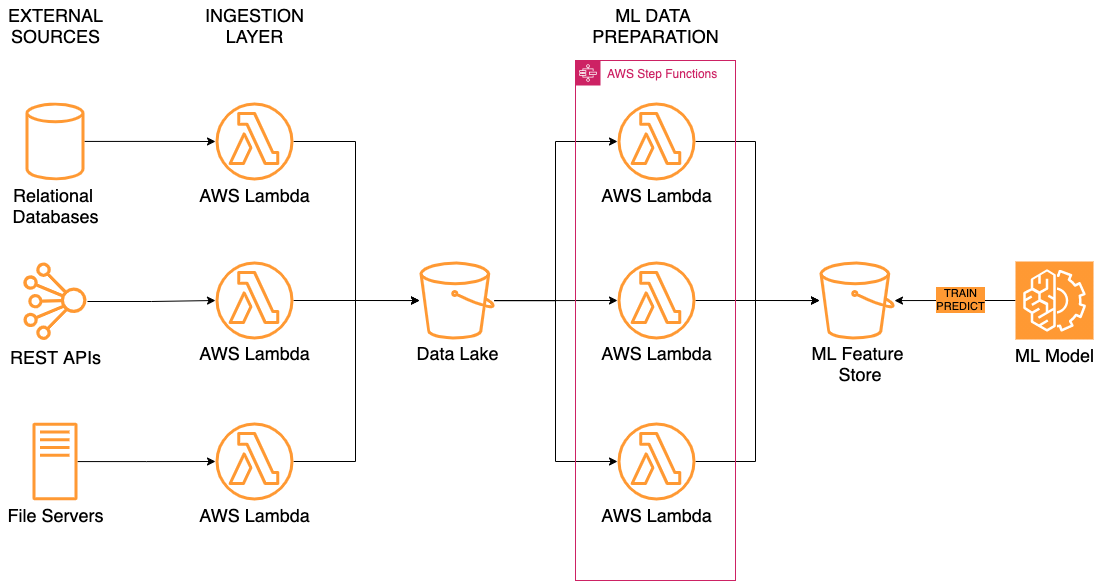
The client has been building a data platform for data science use cases. The goal was to ingest vast amounts of data from disparate sources, transform and enrich ingested data for unified representation, as well as provide the result to machine learning models for training and prediction.
The data flow comprises the following components:
– Ingestion Layer: The set of tools and pipelines that enable data acquisition from different sources, such as relational databases, REST APIs, semi-structured file formats, studies, and other documents.
– Data Lake: The centralized storage for all data assets with complete governance including inventory, provenance, access control, and audit.
– Batch Layer: The set of pipelines that cleanse, format, enrich, and label data for further ML model training.
– Feature Store: The single place to keep, curate, and serve features to machine learning (ML) models.